Senior devs only need to know one DB. Forget all the others
Unlearn what you think you know, and become a cloud ninja by taking the database back to basics.
Senior devs only need to know one DB. Forget all the others

Here’s a terrifying scenario:
- Your database cost more last quarter than your engineering payroll. Guess which one the CFO is coming to slash first?
- You bet the farm on Postgres, but now just tuning the indexes takes 6 months. There’s cloud resources you could use but they don’t do what Postgres does.
What’s your move?
Here’s your real problem – you know a DB not the DB. The DB you need to know isn’t MySQL, or Postgres, or Mongo — it’s the database broken down into its primitive parts. Once you know the moving parts, you can reassemble the optimal data solution anywhere.
The elephant in the room:
- The RDBMS (postgres, MSSQL & MySQL) were such an end all solution before the modern cloud that they became synonymous with the word “database”
What even motivated me to do this article was the level of “scrapping” I’ve been doing online with senior devs telling me to fix hard problems by ditching the serverless portions of my stack for postgres.
I think the state of most “at scale” ventures is a lot of EC2 (virtual machine) instances running an RDBMS with some cloud resource orchestrating. This is a well understood design, but very heavy on maintenance and has pressure points when scaling up and down. Not to mention there's an implementation floor - if you want to add a new app to your offerings, you probably don’t want to manage a whole RDBMS cluster.
Here’s the lesson - stop living with fundamentally inefficient, monolithic designs because you don’t understand how to integrate cloud resources built to solve cloud problems. Go back to the fundamentals - what is a database.
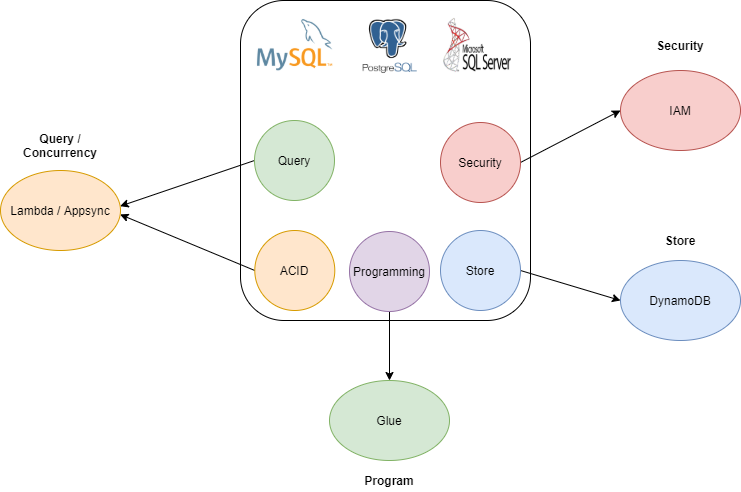
What does a DB really does:
- Security: every DB is useless without it.
- Store: at the end of the day, it’s just key-value.
- Query Layer: the real bottleneck.
- Concurrency: where real engineering happens. (ACID control of requests. )
- Programmability: what separates tools from toys. You’ll need to run clean up, scripts, etc
The way the cloud is going, each one of these tasks are no longer being handled by a monolithic program called the RDBMS. They’re being handled by large clusters that do one of these jobs each. Though I will say the challenge here is the query layer, the other four features are fully satisfied and more advanced than ever. So let’s look at the serverless cloud, which is currently the most distributed offering. Here’s an AWS example of how we implement this.
Security – IAM (Identity Access Management) is account wide. Its not specific to your application so you’re responsible for setting limited scope for the corner of the cloud you want to secure. The first thing you’ll do with AWS is set up the IAM roles you would use for a database. There should be roles for DDL admins, who can alter anything about your stack, there should be an internal query role, and there should be a user role.
Store – DynamoDB is a key value store that works by keeping isolated partitions. DynamoDB stores records as a “partition key” which determines which partition (actually cluster storage resource) will house the data. Then there is a sort key, which will be the only column by which the data is sorted. Beyond these two keys you can store any type of data you want as schema-less. The data will not be typed by the database, it will not be queryable. Indexes can be generated which will actually store copies of the dataset organized into different partitions with different sort keys. Data must be retrieved by passing the combination of partition key and sort key for the data. Alternatively you can list the data in a partition. This is the point where everyone says:
The penalty for serverless is a little latency for pulling the data out of Dynamo DB, and all the indexes are materialized. Other than that it is exactly the same as your RDBMS – trust me 😉
Query Layer – Lambda. Okay what magic is there here? Answer – None. Nor was there any magic inherent to how your RDBMS was executing SQL. (actually if you're hung up on SQL there is a service to implement that but I don’t advise it at scale due extra cost overhead). In fact if you look at the query plan in your favorite RDBMS you can actually implement the exact same pattern of steps using python or javascript via lambda. Lambda is a cluster of running cpus that just compute when a request is submitted. In fact you’ll find every RDBMS does the same thing - it pulls the data from a key value store on disk and then runs the WHERE filter of the data in the CPU. The nice thing about python is that it’s actually fast if done right, because pandas and spark are set up to execute data operations like joins and merges in optimized C and not the python interpreter.
Concurrency – Know your patterns. This is where a lot of people will break down. (I’m especially looking at you MSSQL devs.) All the necessary data patterns for defining how ACID is handled by your queries for concurrency have always been available. There’s a whole list of concurrency patterns according to me that all senior db devs should know. If you think that AWS aught to have a better solution than relying on stupid, dum, developers to do things smart – I get where you’re coming from. However, that’s the case right now. It’s not too hard, but it’s on you. Study up. Remember a fleet of other devs have paved the way so be thankful for patterns. You can also reference my other article Concurency Patters You Can Actually Use
Programmability – Glue. Aws maintains a cluster of always running apache spark workers. If you’re not familiar with spark yet let me fill you in. It’s a Hadoop cluster of machines that are constantly running a python environment that can be used to read data from your store, can cache the data in S3 in parquet (a columnar data format that allows quick set based computation) or any other format you choose. Glue is the primary place to do your UDF in the AWS serverless ecosystem. You simply start a session, and then queue your code to run in the persistent cluster. Within moments your code is orchestrated out to the cluster, and runs against resources you have IAM permission to access.
Maybe after all this ranting of mine, you can see why I almost gave up hope on the human race when a community of advanced developers assured me that I would need a real RDBMS and that a key value store like dynamodb wouldn’t work. And the best part is you don't have to choose postgres or this whole stack. If you really evaluate your strengths and weaknesses you can mix and match cleverly to get the result you want.
There is only one db a senior dev truly needs to know. That is the one you can make secure, persistent, accessible, concurrent, and programmable. If you understand the basic legos you can work easily with any db resource you choose.